Overview
This guide assumes you already have a basic understanding of HTML and CSS.
If you are not already familiar with these subjects, we recommend taking our 30-minute Intro to HTML & CSS course for non-technical users prior to reviewing this guide.
Hierarchy of Elements on a Web Page
As a brief refresher, a web page is divided into two basic components: the <head> and the <body>. The <head> contains information about what is going to be loaded on the page, such as scripts, styles, and other metadata elements. The <body> is where all of the HTML content of the page is rendered, though it can also contain scripts and styling.
CSS Selectors
CSS selectors allow you to target specific HTML elements and apply styling rules to them, such as indicating what size they should be, where they should sit in relation to other elements on the page, if something should change if the element is hovered or clicked on, and more. For a more in-depth introduction to CSS selectors, see this page on How CSS Selectors Work.
There a few different tools within Heap you can use to label events.
- Using visual labeling, which is Heap’s simple point-and-click interface for labeling events. While labeling a new event via visual labeling, the CSS selectors targeting that event are displayed in the visual labeling interface. Understanding this information is helpful for confirming that you’ve labeled your event correctly.
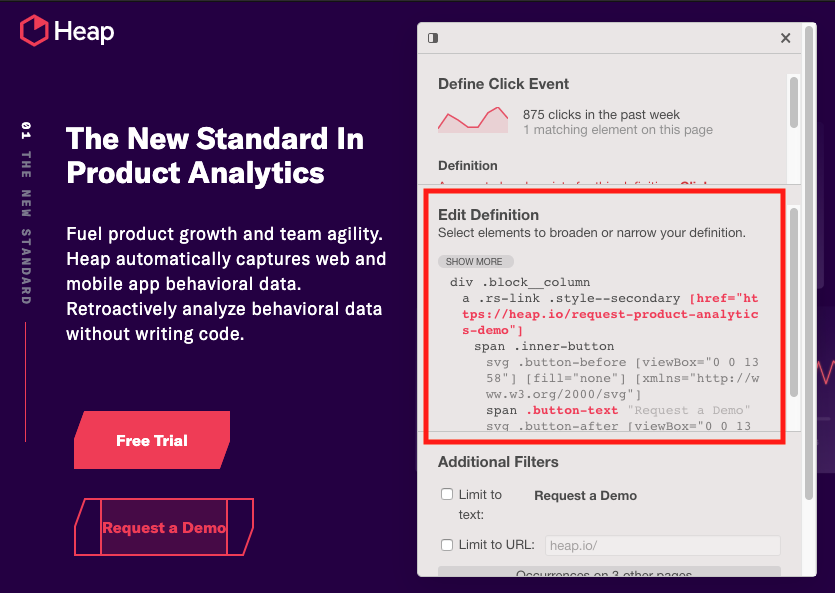
- Using the events page: when you label a new event on the events page, if the event is a Click on, Submit on, or Change on type, a field will appear for you to label the CSS selector.
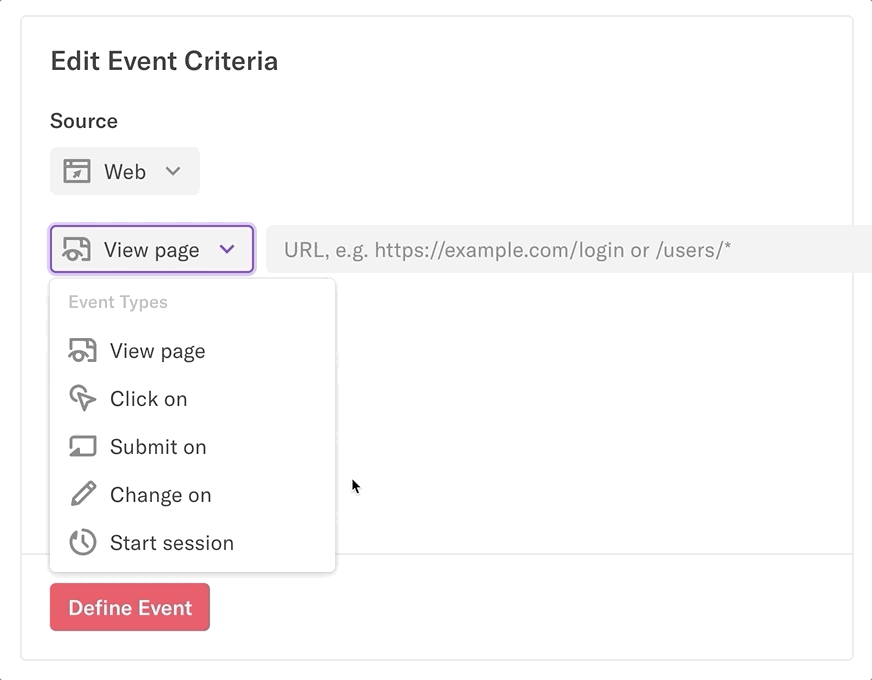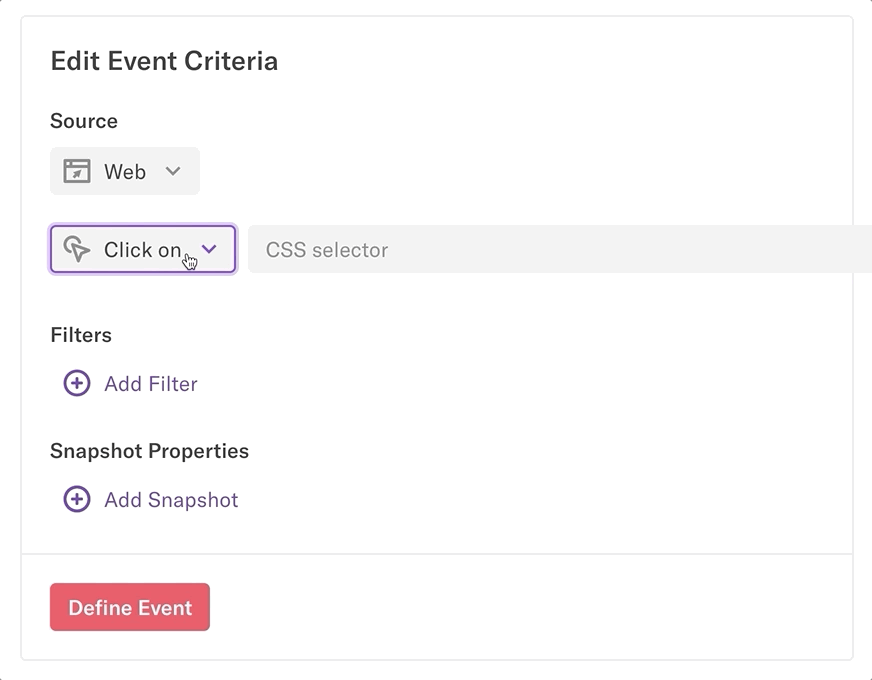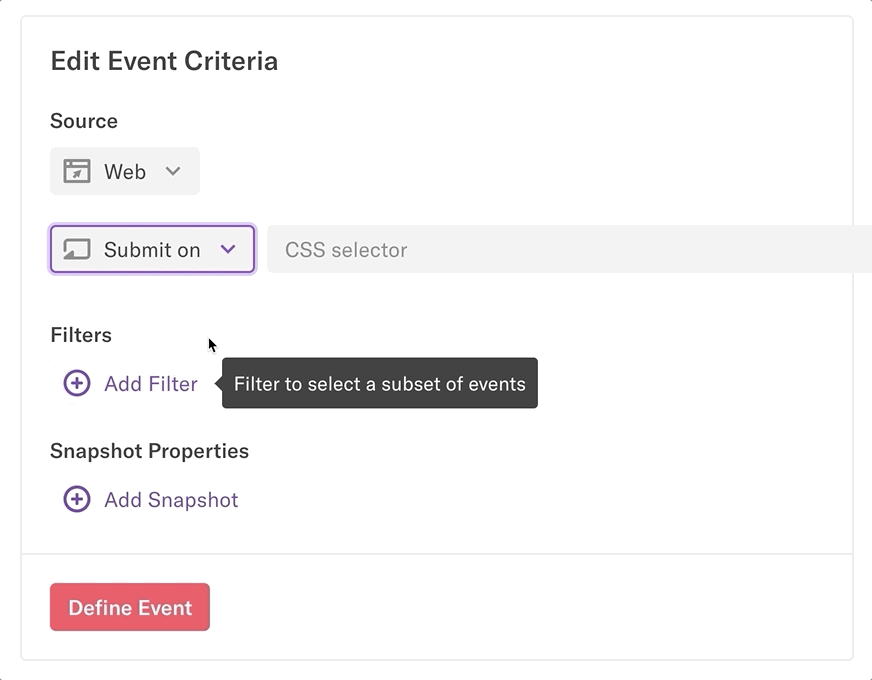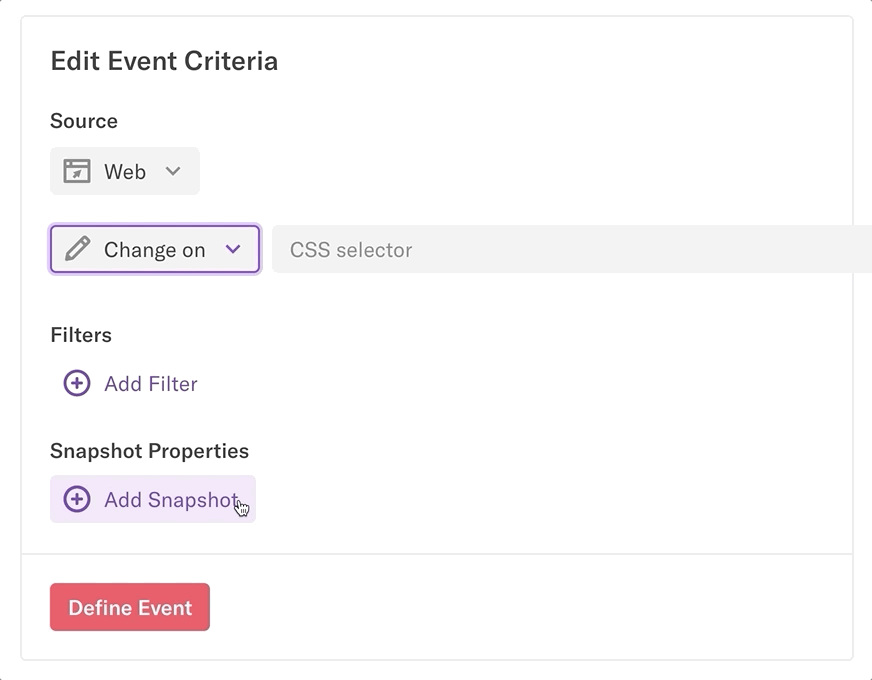
Heap uses CSS selectors to target select elements on your website and track interactions associated with that event. These CSS selectors map your website via the attributes in your HTML.
Tags
Tags define the hierarchy of elements on an HTML page. They are always surrounded by <> angled brackets. Some tags are a combination of opening and closing tags, while others, indicated by the presence of a forward slash <\> in the tag, are self-closing. Most tags encapsulate content or other tags.
In Heap, we define the hierarchy of an individual element by describing the opening tags that lead up to it, separated by spaces. As an example, for the hierarchical tag elements on this simple HTML page:
<div>
<span>This is a <b>cool</b> tag</span>
</div>We have a <b> inside of a <span> inside of a top-level <div>, so when writing CSS selectors in Heap, we would capture the element that encompasses the “cool” text by using the following notation:
div span bThis notation is used to map raw data to events in Heap. Heap captures the entire hierarchy from the element up, then in the Heap interface, you can use the above syntax to map that raw data to one or more elements on your page.
The notation above captures the element we are looking to target in our simple example, though a selector like this might easily match multiple elements on a more complex webpage. Let’s get into how we can use attributes, including IDs and classes, to accurately capture the element(s) we want on more complex pages.
Attributes
Attributes are values that apply rules to an element on a webpage, such as specifying the width and height of an image. Attributes are always specified in the start tag (or opening tag) and usually consists of name/value pairs like name="value", ex. width=”50”.
Heap uses attributes to map your site’s data to access elements of a webpage. Common attributes that are used in Heap CSS selectors are tags, IDs, and classes.
For more info on how Heap uses attributes in event definitions, including a list of simplified attribute selectors you can use, and a list of attributes we currently do not capture, see the attributes section of How to define events for web, mobile, react, and angular apps.
Data-Attributes
Data-attributes are a great way to store extra attribute information on standard, semantic HTML elements without requiring other hacks such as non-standard attributes, or extra properties on DOM.
A data-attribute is simple to add and identify: any attribute on any element whose attribute name starts with data- is a data attribute. When creating an event, remember to use square brackets around the data-attribute. For example: [data-heap="separate-inviter-installer-card"].
IDs
The ID attribute can be used to include a unique name to apply a certain set of styles to one specific element in the hierarchy of your webpage. An ID is meant to be absolutely unique. That means that only one element on a page should have a particular ID.
In an HTML tag, an ID shows up as an attribute with a single string value, like this:
<span id="firstTag">This is a <b>span</b> tag</span>Using the CSS selector notation we learned above, we can include an ID right after the tag name (no space needed):
span#firstTag bThis selector says, select the span with the ID of firstTag and the child tag <b>. The # hash character is used to differentiate the ID from a tag.
This notation allows us to avoid the issue of matching multiple elements on a page. However, if you have multiple elements nested in an ID tag which are not unique, such as in this example:
<span id="firstTag">This is a <b>span</b> and this is a second <b>bold</b> element</span>The notation above could erroneously match both of the <b> elements. To prevent this from happening, you’d want to modify your HTML to add an ID (or any other type of attribute) to the bold element you wish to capture with a unique CSS selector.
Classes
Like IDs, the class attribute is used to include additional names for all page elements which are meant to have the exact same style. In Heap, we use classes as part of the CSS selector to match the right element(s) on the page.
For this example:
<span id="firstTag" class="red">This is a <b class="blue">span</b> and this is a second <b class="green">bold</b> element</span>We write the following selector to access only the first element of the class “blue”. The . period character is used to differentiate the class from a tag.
span#firstTag b.blueWe add the period before the class name, and put it after the tag. If an ID is present, after the ID. Now we won’t accidentally select the other span#firstTag b element, since it doesn’t have a class of blue.
Aria Labels
Aria labels provide a text alternative to an element that has no visible text on the screen and are typically used for accessibility purposes.
Heap is set up to prioritize aria labels whenever it makes sense to do so. For each element in the hierarchy, Heap pulls out one type of token – either ID, attributes, classes, or tags. During the evaluation process, attributes are sorted according to their original order and the priority assigned to each specific attribute key.
For example, aria labels are prioritized below data-attributes, which are scored above most other attributes. Starting from the highest priority attributes, Heap checks the attribute’s uniqueness within the entire DOM and its local DOM subtree. If chosen it’s added to the selector, and any other attributes are skipped.
Because aria-label is now the highest priority attribute, if it fits the uniqueness criteria, it will likely be present in the final selector.
Best Practices for Writing CSS Selectors
CSS character limit
Heap has a 1024 character limit for parent hierarchy capture and truncation.
If there are too many characters in the hierarchy between the child selector and the parent selector, your definition won’t work.
Selectors only need to be as specific as you want them to be. You can leave things out, as long as leaving something out doesn’t make the selector more broad than you intended.
There are many different ways to write the same selectors. As an example, for the above HTML, the following selectors all mean the same thing:
span b.blue
span .blue
#firstTag .blue
#firstTag b.blue
.blue
b.blue
.red .blue
.red b.blue
span#firstTag.red b.blueEach element of a selector is separated by a space, if a tag is present, it should be the first thing in each part of the selector. After that, if an ID is present and used, it should either immediately follow the tag, or be the first if no tag is present. Finally, any class or classes should come last, after a tag or ID if they are present, and there can be more than one class on a single element.
Pageview events
What triggers a pageview?
For details on what triggers a pageview, see How does Heap define a pageview?
Recommended pageview events & properties
There are four key properties sprovided by the pageview URL, which you can draw off of to set up your pageview: domain, path, query, and hash.
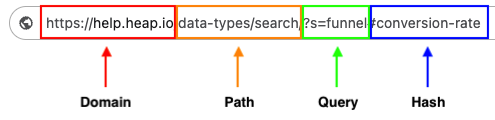
We’ve provide a list of recommended pageview events to create based on the popularity of those pages. Setting up these pageviews as events allows you to dig into engagement with those pages to better understand user behavior. For more info, see Pageview Suggestions.
Best practices for defining pageviews
Here are some best practices for creating pageview events:
- Though you can create pageview events based on any of the four properties above, for accuracy, we recommend creating pageview events based on their path or hash.
- To track views on elements that don’t trigger a pageview (URL change), such as pop-ups or SPAs, use custom track events.
- If the URL structure of your site changes, let your Heap admin know so they can update events accordingly. You can also use Heap’s event repair flow to evaluate and fix broken events.
Click events
What triggers a click?
A click is defined as a click on any element on the page or screen.
What key properties does Heap capture from a click?
Heap captures a variety of properties related to clicks, including domain, path, query, hash from URL, target tag, class, ID, and the hierarchy of the event that was clicked on. For a full list of autocaptured properties, see Autocaptured Data.
Best practices for creating click events
Here are some best practices for setting up click events:
- Make sure elements of key features have unique IDs, classes, or accessibility labels (ex: aria-* or data-*) and that the language is consistent (ex. English).
- Make sure that the ID, class or attribute is not too specific or too general.
- If a button, such as a save button, can show up in multiple spots, make sure something in the hierarchy and/or URL identifies which exact button it is.
- If you’re making a site change that might affect element IDs, classes or accessibility labels, let your Heap admin know so they can update events accordingly. You can also use Heap’s event repair flow to evaluate and fix broken events.
Change on and Submit events
What triggers a change on or submit event?
A change on event is triggered when a user changes the value of an input field (text box, radio button, check box).
A submit event is triggered when a user clicks on a submit button (button where type=”submit”) within a form (<form>).
What key properties does Heap capture from the change/submit event?
Heap captures the same properties as a click event, with the exception of any text within a text input field (we will capture that the field has been changed, but not the text within it).
Best practices for creating change on and submit events
Here are some best pratices when creating change on and submit events:
- If possible, do form validation before allowing users to submit it – if this step is done after the button click, it may cause an inflated count of submissions.
- If you’re making a site change that might affect element IDs, classes or tags, let your Heap admin know so they can update events accordingly. You can also use Heap’s event repair flow to evaluate and fix broken events.
Snapshots
What are snapshots?
Snapshots give you the ability to capture additional metadata about actions that are occurring on your site beyond what Heap captures out-of-the-box.
There are 3 types of snapshots you can create:
- Text in element
- Form value
- Value of JavaScript
Best practices when creating snapshots
Here are some best pratices when creating snapshot events:
- Be careful to avoid capturing sensitive data in snapshots. For guidance on collecting sensitive data, see How do I hide sensitive elements within Heap?
- If you wish to capture radio button form selections, you can use the Form value type, though all radio options must have the same value for the name attribute.
- Using attributes, like aria-selected=”true” to flag selected options from a drop-down makes creating snapshots easier.
- If you’re making a site change that might affect element IDs, classes or tags, let your Heap admin know so they can update snapshots accordingly. Snapshots aren’t retroactive, so if anything breaks, that data won’t be collected until it is fixed.
All of the rules described earlier in this guide for selectors also apply to snapshots, though they also allow for a few more CSS rules.
Pseudo-classes are selectors that only select elements when they are in a specific state, such as when a user is hovering over something. They can be used in snapshot definitions, but not regular event definitions, because snapshots run on the client-side while the user is on your page, so the specific state is only available at that time.
For snapshot use cases, see Snapshots overview.
Dynamic CSS
Be careful when using dynamic CSS IDs or classes, which includes most IDs you see with a random string of numbers or classes (such as ember_12345) as these may limit the data captured to the extent that nothing appears in Heap. Even if data does show up at first, event definitions that use dynamic CSS will break once the site is updated and the dynamic class names change. If you see no users have completed this action in your analysis, this means you probably have a dynamic CSS class or ID selected.
React CSS
React libraries that implement CSS modules do non-conventional things to the HTML code on the page. They may completely replace semantic class names with short, random strings. They may preserve some semantically useful information, but may also append a random string to the end of the class, which changes on each build. Some implementations may only use a data-react-id attribute that has no semantic value (typically just a number) and that Heap, accordingly, doesn’t track.
For best practices on using Heap with React websites, see Using Heap with React Websites.