This feature is only available to customers on the Premier plan or the Pro plan as an add-on. To upgrade, contact your Customer Success Manager or sales@heap.io
This integration is Destination only, meaning you can send data out of Heap but not send data into Heap.
Overview
Heap Connect for Amazon S3 enables any downstream system (ex. Hadoop, Stitch, Fivetran) to access Heap data at scale. This allows you to reap the benefits of codeless event creation, retroactivity, and cross-device user identity.
ETL Consideration
Heap Connect for S3 is designed to support building a custom data pipeline, not for querying directly in an Enterprise Data Lake. Interested customers will need to work with one of our ETL partners or provision Data Engineering resources that will build and maintain a data pipeline.
Setup
Prerequisites
To connect this integration, you’ll need the following permissions:
- Admin or Architect privileges in Heap
- Appropriate permissions in your S3 account to create buckets and modify bucket policy
Step 1: Create S3 Bucket(s) with the provided bucket policy
In your Amazon S3 account, create an S3 Bucket prefixed with the name “heap-rs3-” and add the bucket policy below.
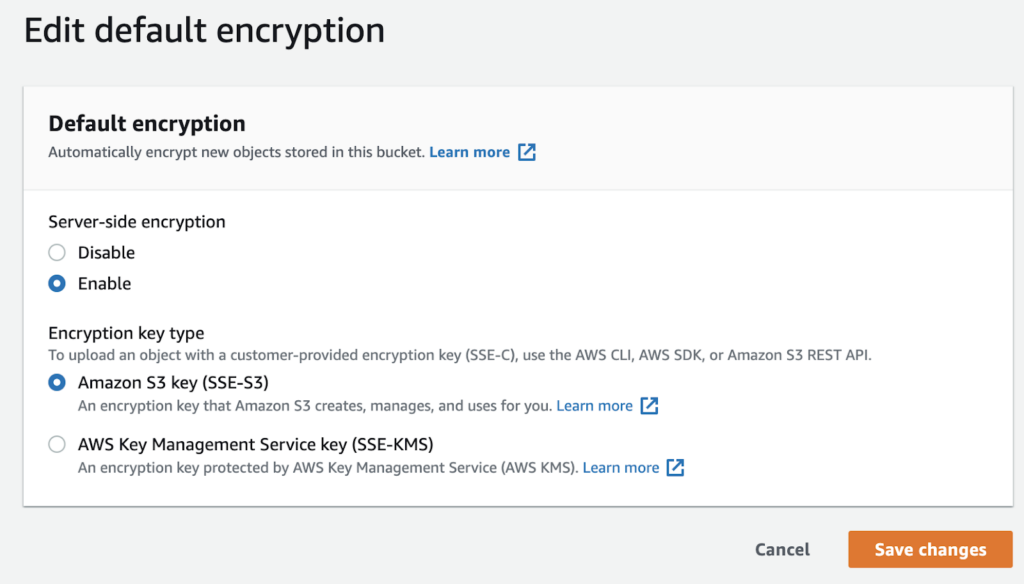
In terms of server-side encryption, Heap currently supports only the Amazon S3-managed keys (SSE-S3) encryption key type. Buckets using the AWS Key Management Service key (SSE-KMS) encryption key type are not currently supported.
No additional user/role in S3 is required.
For instructions on how to edit your bucket’s default encryption, please see AWS’ documentation.
Multiple Environments
If you have multiple environments syncing to S3, you should use a different bucket for each.
Bucket Policy
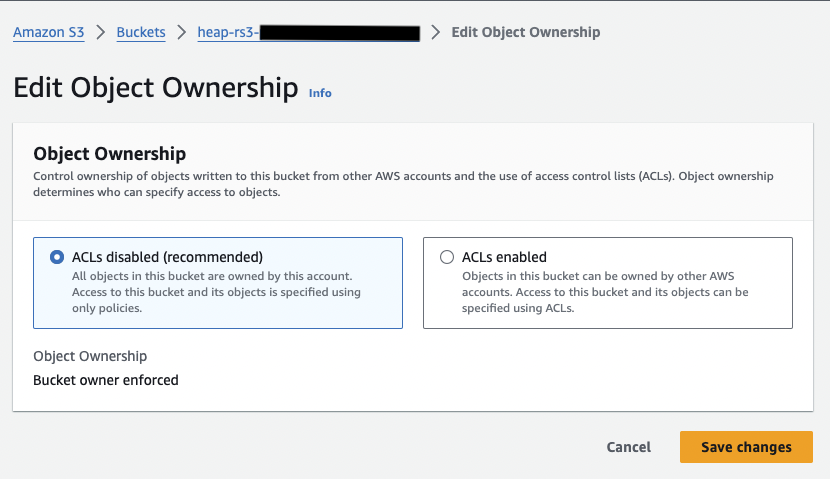
Heap requires the S3 Object Ownership setting “Bucket owner enforced (recommended)”.
If you would like to restrict the allowed actions, the minimum required actions are: s3:DeleteObject, s3:GetObject, s3:ListBucket, s3:PutObject.
Add the following policy to the destination S3 bucket. This policy applies only to the Heap bucket you created specifically for this export. Add your bucket name where indicated and paste this policy into the Amazon console:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1441164338000",
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::<bucket_name>",
"arn:aws:s3:::<bucket_name>/*"
],
"Principal": {
"AWS": [
"arn:aws:iam::085120003701:root"
]
}
}
]
}We also recommend reviewing the following documentation:
- How do I add an S3 bucket policy?
- Bucket owner granting cross-account bucket permissions (Heap is Account B in this scenario)
- Controlling ownership of objects and disabling ACLs for your bucket
Step 2: Heap establishes the connection and creates an initial sync
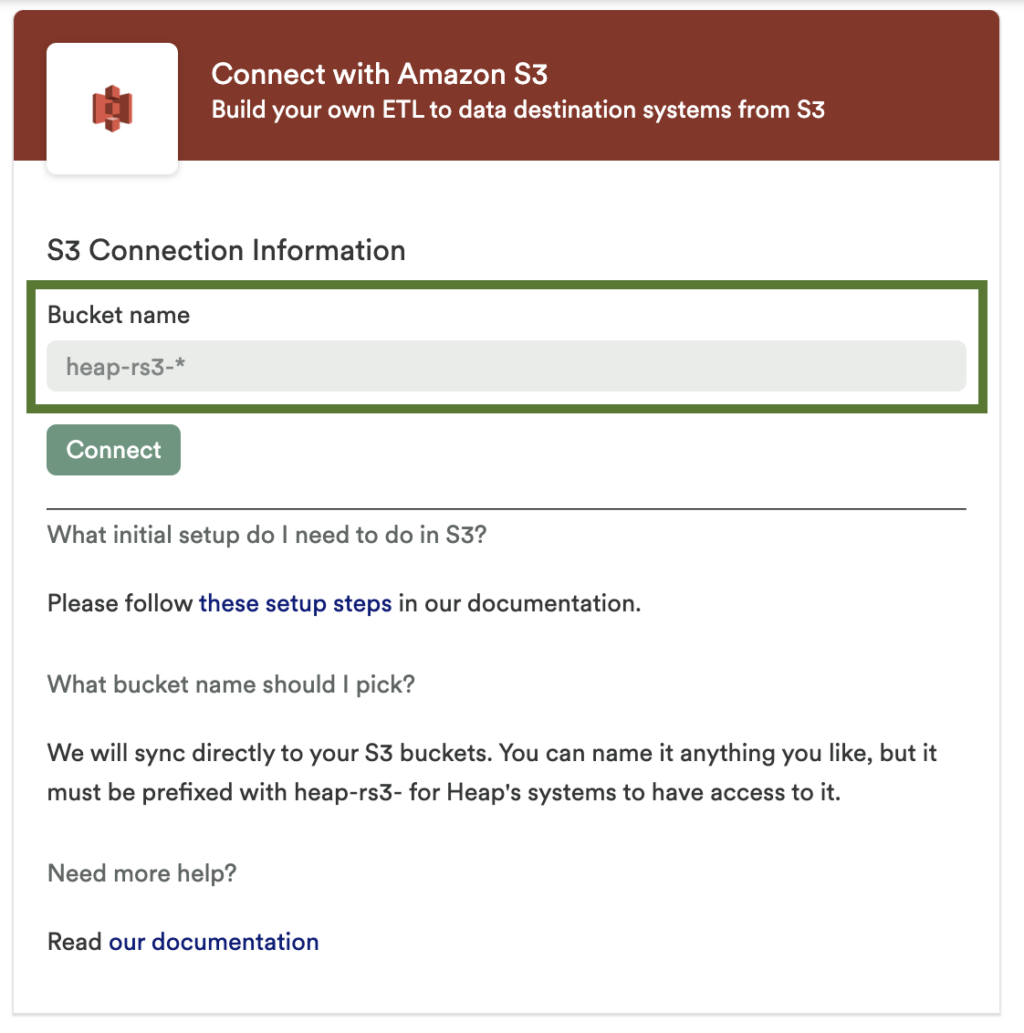
Once the bucket policy is configured, enter the bucket name on the S3 configuration page in Heap and click Connect.
If you’ve created multiple buckets because you have multiple Heap environments, follow Steps 2-4 on a per-bucket basis in each Heap environment.
Then, Heap will initiate the sync of your data to S3. The initial sync contains Pageviews, Sessions, and Users data.
Completion of a sync is signaled by the delivery of a new manifest file. You should poll s3://<BUCKET>/manifests/* for new manifests. Once a manifest is delivered, you can process it via your ETL pipeline. To learn more, see ETL Considerations.
Step 3: Choose additional events to be synced (optional)
Once the connection is established, you can toggle additional individual events in Heap to be synced to S3.
There are multiple places in Heap where you can modify which events are syncing to Heap Connect. Navigate to Integrations > Directory and search for S3 to toggle “on” which events you want to sync to this destination. You can also modify the sync toggle from an individual event’s details page, as well as from the general events overview section of Heap.
For more details on data syncs, please see Managing Data Syncing.
Step 4: Set up an ETL
Your engineering team will need to set up an ETL to port the data into a queryable destination of your choosing.
Keep in mind the following ETL requirements when working with Heap data in S3:
ETL Requirements
- Data across dumps/files are not guaranteed to be disjointed. As a result, downstream consumers are responsible for de-duplication. De-duplication must happen after applying user migrations. We recommend the following de-duplication strategy:
| Table | De-duplication Columns |
|---|---|
| Sessions | session_id, user_id |
| Users | user_id |
| Event tables | event_id, user_id |
- Updated users (users with properties that have changed since the last sync) will re-appear in the sync files, and thus every repeated occurrence of a user (check on user_id) should replace the old one to ensure that the corresponding property updates are picked up.
- user_migrations is a fully materialized mapping of from_user_ids to to_user_ids. Downstream consumers are responsible for joining this with events/users tables downstream to resolve identity retroactively. For complete steps, see Identity Resolution.
- For v2, we only sync defined property definitions rather than the actual defined property values. Downstream consumers are responsible for applying these definitions to generate the defined property values for each row.
- Schemas are expected to evolve over time (i.e. properties can be added to the user and events tables)
Process Overview
Heap will provide a periodic dump of data into S3 (nightly, by default). That data will be delivered in the form of Avro-encoded files, each of which corresponds to one downstream table (though there can be multiple files per table). Dumps will be incremental, though individual table dumps can be full resyncs, depending on whether the table was recently toggled or the event definition modified.
We’ll include the following tables:
- users
- pageviews
- sessions
- toggled event tables (separate tables per event)
- user_migrations (a fully materialized mapping of users merged as a result of heap.identify calls)
Metadata
Each periodic data delivery will be accompanied by a manifest metadata file, which will describe the target schema and provide a full list of relevant data files for each table. Note: Please ignore any files in the data delivery that aren’t listed in the manifest metadata file.
It includes the following information:
- dump_id: A monotonically increasing sequence number for dumps.
- tables: For each table synced:
- name: The name of the table.
- columns: An array consisting of the columns contained in the table. This can be used to determine which columns need to be added or removed downstream.
- files: An array of full s3 paths to the Avro-encoded files for the relevant table.
- incremental: A boolean denoting whether the data for the table is incremental on top of previous dumps. A value of false means it is a full/fresh resync of this table, and all previous data is invalid.
- property_definitions: The s3 path to the defined property definition file.
An example of this metadata file can be found below:
{
"dump_id": 1234,
"tables": [
{
"name": "users",
"files": [
"s3://customer/sync_1234/users/a97432cba49732.avro",
"s3://customer/sync_1234/users/584cdba3973c32.avro",
"s3://customer/sync_1234/users/32917bc3297a3c.avro"
],
"columns": [
"user_id",
"last_modified",
...
],
"incremental": true
},
{
"name": "user_migrations",
"files": [
"s3://customer/sync_1234/user_migrations/2a345bc452456c.avro",
"s3://customer/sync_1234/user_migrations/4382abc432862c.avro"
],
"columns": [
"from_user_id",
"to_user_id",
...
],
"incremental": false // Will always be false for migrations
},
{
"name": "defined_event",
"files": [
"s3://customer/sync_1234/defined_event/2fa2dbe2456c.avro"
],
"columns": [
"user_id",
"event_id",
"time",
"session_id",
...
],
"incremental": true
}
],
"property_definitions": "s3://customer/sync_1234/property_definitions.json"
}Data Type
The user_id, event_id, and session_id are the only columns that are long types. All other columns should be inferred as string types.
Sync Reporting
Each sync will be accompanied by a sync log file that reports on delivery status. These log files will be placed in the sync_reports directory. Each report will be in a JSON format as follows:
{
"start_time":1566968405225,
"finish_time":1566968649169,
"status":"succeeded",
"next_sync_at":1567054800000,
"error":null
}start_time, finish_time, and next_sync_at are represented as epoch timestamps.
You can learn about how the data will be structured upon sync by viewing our docs on data syncing.
Defined Properties JSON File
We’ll sync defined property definitions daily and provide a JSON file containing all defined properties and their definitions. Downstream consumers will be responsible for applying these definitions to generate the defined property values for each row.
The JSON file format is an array of property definitions:
Conditional Properties
The schema for conditional properties is as follows:
{
"property_name": "Channel",
"type": "",
"cases": [
{
"value": {...}, // Refer to values spec below
"condition": {...} // Refer to conditions spec below
}
],
"default_value": {...} // Refer to values spec below. This field is optional
}Formula Properties
The schema for formula properties is as follows:
{
"property_name": "Channel",
"type": "",
"data": {...} // Refer to formula spec below
}Formula Values
A formula contains a function and a number of arguments which can either be a property value (as specified below) or another nested formula. The number and meaning of the arguments depends on the function.
The possible formulas are:
{
"function": "value",
"arguments": [
{...} // Refer to values spec below
]
}{
"function": "uppercase",
"arguments": [
{...} // This is another formula and represents the value to convert to uppercase
]
}{
"function": "lowercase",
"arguments": [
{...} // This is another formula and represents the value to convert to lowercase
]
}{
"function": "concat",
"arguments": [
{...}, // This is another formula and represents the first value to concatenate
{...} // This is another formula and represents the second value to concatenate
]
}{
"function": "addition",
"arguments": [
{...}, // This is another formula and represents the first summand
{...} // This is another formula and represents the second summand
]
}{
"function": "subtraction",
"arguments": [
{...}, // This is another formula and represents the minuend
{...} // This is another formula and represents the subtrahend
]
}{
"function": "multiplication",
"arguments": [
{...}, // This is another formula and represents the multiplier
{...} // This is another formula and represents the multiplicand
]
}{
"function": "division",
"arguments": [
{...}, // This is another formula and represents the dividend
{...} // This is another formula and represents the divisor
]
}{
"function": "coalesce",
"arguments": [
{...}, // This is another formula and represents the first value to coalesce
{...} // This is another formula and represents the second value to coalesce
]
}{
"function": "regexp_extract",
"arguments": [
{...}, // This is another formula and represents the regular expression pattern
{...} // This is another formula and represents the source string
]
}{
"function": "conditional",
"arguments": [
[
{
"where": {...} // Refer to conditions spec below
"value": {...}
// This is another formula and represents the value when this condition is met
}
],
{...} | null
// This is another formula representing the default value to use when no conditions are met
]
}Property Values
The argument to a value formula, value in cases, and the default_value can be a constant or another non-defined property on the same entity (e.g. event defined props will only refer to other properties on the event).
{
"type": "",
"value":
}Conditions
Each case produces a value for the defined property if the conditions evaluate to true. Notes:
- Case statements are evaluated in order, so if the cases aren’t mutually exclusive, the value of the defined property will come from the first case to evaluate to true.
- We currently only support 1 level of condition nesting beyond the top level, but this format can support more than that.
- The conditions can be traversed to represent the logic in another format just as SQL case statements.
{
"clause_combinator": "",
"clauses": [...] // Refer to clauses spec below
}Clauses
{
"property_name": "utm_source",
"operator": "...", // Refer to operators spec below
"value": ... // Refer to clause values spec below
}Operators
These are the names we give operators internally. They’re reasonably readable, so we can just use them.
| Operator | Description |
|---|---|
| = | Equal |
| != | Not Equal |
| contains | Contains |
| notcontains | Does not contain |
| isdef | Is defined |
| notdef | Is not defined |
| matches | Wildcard matches (SQL equivalent of ILIKE) |
| notmatches | Doesn’t wildcard match (SQL equivalent of NOT ILIKE) |
| includedin | Included in a collection of values |
| notincludedin | Not included in a collection of values |
Clause values
All operators but includedin and notincludedin have string values. includedin and notincludedin values are supplied via a file in the property definition. Internally, we store the contents of the file (split by newline) as a JSON array. We can keep using this representation.
Example defined properties file
[
{
"property_name": "channel",
"type": "event",
"cases": [
{
"value": {
"type": "constant",
"value": "Social"
},
"condition": {
"clause_combinator": "or",
"clauses": [
{
"clause_combinator": "and",
"clauses": [
{
"property_name": "campaign_name",
"operator": "=",
"value": "myfavoritecampaign"
},
{
"property_name": "utm_source",
"operator": "=",
"value": "facebook"
}
]
},
{
"property_name": "utm_source",
"operator": "=",
"value": "instagram"
}
]
}
},
{
"value": {
"type": "property",
"value": "utm_source" // This is a property on the event
},
"condition": {
"clause_combinator": "or",
"clauses": [
{
"property_name": "utm_source",
"operator": "=",
"value": "google"
},
{
"property_name": "utm_source",
"operator": "=",
"value": "bing"
}
]
}
}
],
"default_value": {
"type": "constant",
"value": "Idk"
}
},
{
property_name: 'welcome_users',
type: 'user',
data: {
function: 'concat',
arguments: [
{
function: 'value',
arguments: [
{
type: 'constant',
value: 'Hello, ',
},
],
},
{
function: 'coalesce',
arguments: [
{
function: 'value',
arguments: [
{
type: 'field',
value: 'identity',
},
],
},
{
function: 'value',
arguments: [
{
type: 'field',
value: 'user_id',
},
],
},
],
},
],
},
},
]Time in S3
On the users table, joindate and last_modified are in UNIX timestamp format:
"joindate" : 1642266296354000,
"last_modified" : 1642529126100000,
On the sessions, pageviews, and other event tables, the time column is in a “traditional” timestamp format: "time":"2021-11-24 18:51:30.138"
Limitations
Please note that your organization will need to manage the ETL process yourself. We do not perform deduplication or identity resolution. To learn more, see the ETL Requirements section above.