This feature is only available to customers on paid plans. To upgrade, contact your Customer Success Manager or sales@heap.io.
Heap Connect lets you directly access your Heap data in BigQuery. You can run ad-hoc analyses, connect to BI tools such as Tableau, or join the raw Heap data with your own internal data sources.
Best of all, we automatically keep the SQL data up-to-date and optimize its performance for you. Define an event within the Heap interface, and in just a few hours, you’ll be able to query it retroactively in a clean SQL format.
Setup
To start accessing Heap Connect data through BigQuery, you’ll require an existing Google Cloud project. After some initial setup of your project, all that needs to be done is to add our Heap service account as a BigQuery user, and share your project ID with us. All of these steps are detailed below.
Connection Requirements
Prerequisites
Before starting the Heap Connect BigQuery connection process, you’ll need to:
- Have a Google Cloud Platform (GCP) project. If you don’t already have a project created, you can learn how to do so.
- Enable billing in the GCP project. If you haven’t already done so, you can follow these instructions.
- Enable the BigQuery API. If you haven’t already done so, you can begin the process.
- Know the region you want to use (see Supported Regions).
- Decide on a name for your dataset (optional, default is project_environment).
These prerequisites are also outlined in GCP’s quick-start guide.
Next, proceed as follows:
1. Authorize Heap access to BigQuery
Within the GCP dashboard for your selected project, please visit IAM & admin settings and click + Add.
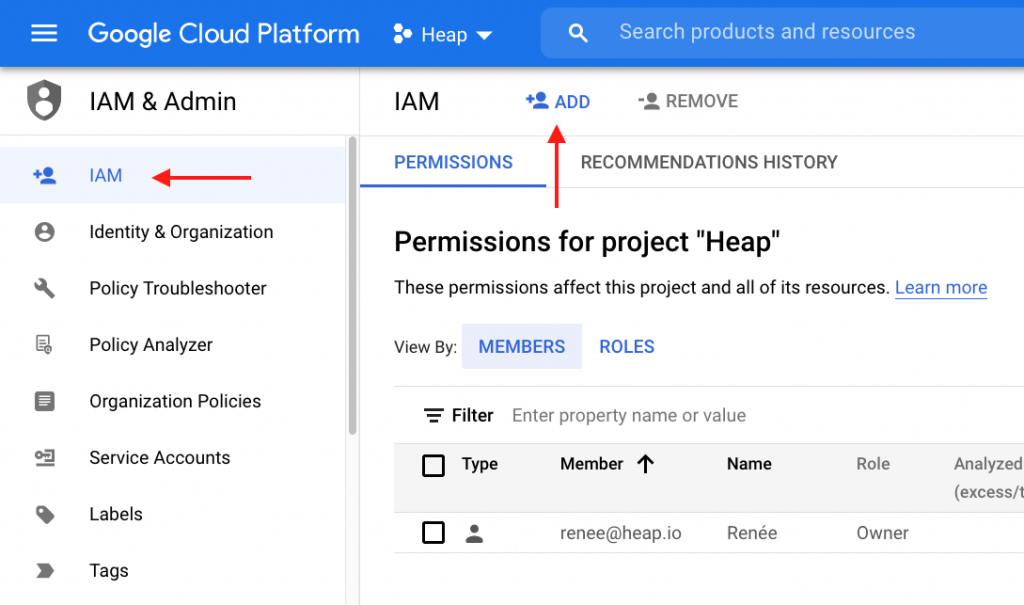
In the subsequent view, add heap-sql@heap-204122.iam.gserviceaccount.com as a BigQuery User and save the new permission.
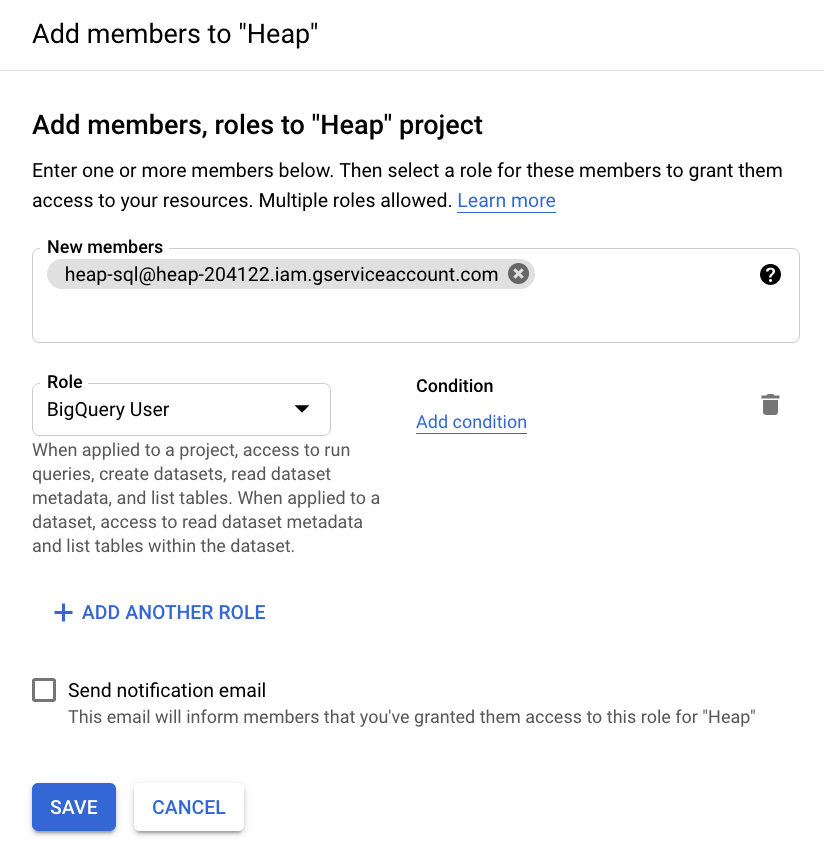
We would prefer to be added as a BigQuery user per the steps above. At minimum, we need to be assigned to a dataEditor role, and we need the following permissions:
Project Permissions
bigquery.datasets.getbigquery.jobs.create
Dataset Permissions
bigquery.routines.createbigquery.routines.deletebigquery.routines.getbigquery.routines.listbigquery.routines.updatebigquery.tables.createbigquery.tables.deletebigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updatebigquery.tables.updateData
See BigQuery’s access control doc to learn more about the different roles in BigQuery, and see this StackOverflow response for steps to grant individual permissions to create a custom IAM role for Heap.
2. Provide Heap Your Project Details
Once the GCP project is configured, you’ll need to enter the following information on the BigQuery configuration page in Heap:
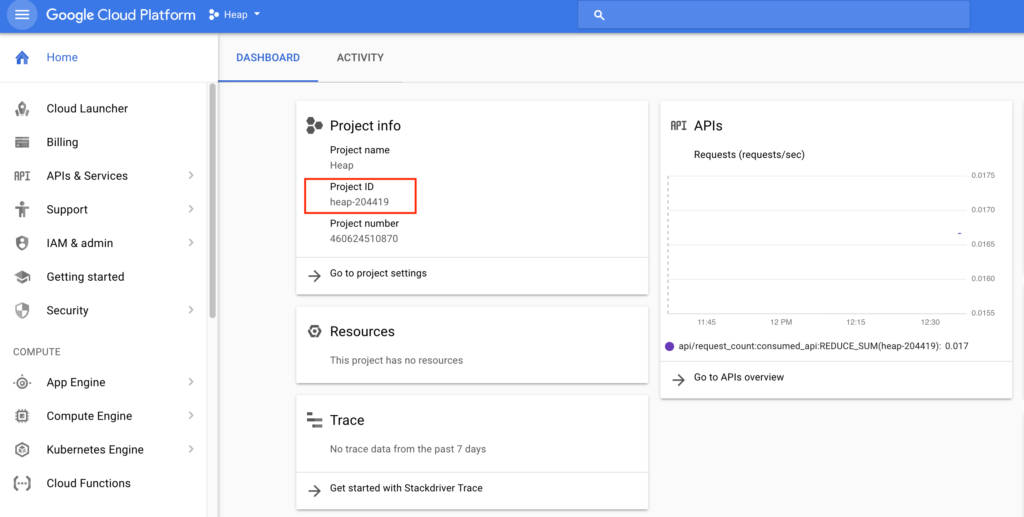
- Your Project ID, which you can find in the
Project infosection of your GCP project dashboard (make sure you’re in the correct project). In the screenshot below, our project ID isheap-204419.
- Your region: we support us, eu, europe-west2, us-central1, us-west1, us-west2, australia-southeast1, europe-west6, and us-east4.
- The dataset name override if you don’t want the default. The default dataset name is project_environment. For example, the Main Production environment will default to a dataset name of main_production.
That’s it! The initial sync should complete within 24 hours. If you don’t see data after 24 hours, please contact us via the Get support page.
You can learn about how the data will be structured upon sync by viewing our docs on data syncing.
Do not create the Heap dataset manually in BigQuery. Heap will create the dataset automatically on the initial sync. Please only provide us with the dataset name you want to use (if you don’t want the default name).
BigQuery Data Schema
The data sync will include two data sets:
- <data set name – default to project_environment> – Includes views and raw tables. Views de-duplicate data but does not apply user migrations.
- <data set name>_migrated – _migrated – Includes views that apply user migrations.
For data accuracy, we recommend querying the views in the second dataset, because these have identity resolution applied. If you want tighter controls over identity resolution (e.g. apply your own identity resolution), you can query the views in the first dataset.
You can sync Defined Properties to this warehouse.
‘Raw’ Tables
Each of the views (except for all_events) is backed by a “raw” table with the name <view_name>_raw. This means that every environment will have both a users view and users_raw table, for example. The views perform deduplication, as the underlying raw tables may have duplicated data introduced during the sync process.
Additionally, the users view filters out users that are from the user in an identify call. For that reason, we recommend querying only against the deduplicated views.
Partitioning
Starting Mar 17, 2021, we will partition new tables synced by using the time column. Partitioning tables by time will result in faster and cheaper query execution when the time column is used as a filter.
To modify tables synced before Mar 17, 2021, to partition by time (‘day’ granularity), you will have to go through a three-step process:
- Create a copy of the table
create table [dataset-name].[table-name]_tmppartition by DATE(time)as select * from [dataset-name].[table-name]; - Drop the original table
drop table [dataset-name].[table-name]; - Copy the temporary table to the new name
Use the BigQuery console to copy the temporary table to the previous table’s name
To learn more about partitioned tables in BigQuery, read Google Cloud’s BigQuery Partition docs.
Supported Regions
Heap supports syncs to the following Google Cloud regions:
- us
- eu
- europe-west2
- us-central1
- us-west1
- us-west2
- australia-southeast1
- europe-west6
- us-east4